Содержание
- Что такое Firecrawl: суть за 60 секунд
- Как работает Firecrawl изнутри
- Полный арсенал возможностей: что умеет делать
- Кому нужен Firecrawl и для каких задач
- Как начать: пошаговая инструкция
- Тарифы и реальная стоимость: без сюрпризов
- Firecrawl vs аналоги: честное сравнение
- Чем Firecrawl помогает маркетологу
- Промпт для ИИ: анализ конкурентов через Firecrawl
- Типичные ошибки при работе с Firecrawl
- FAQ
Что такое Firecrawl: суть за 60 секунд
Firecrawl — это API-сервис (программный интерфейс) для сбора, парсинга (извлечения) и структурирования данных с любых веб-сайтов. Вы даёте ему ссылку — он возвращает чистый текст, разметку Markdown (текстовый формат с заголовками и структурой) или структурированный JSON (формат данных, понятный любому приложению).
Главная фишка: данные выдаются сразу в формате, пригодном для LLM. Никакой мусорной рекламы, навигационных меню и лишнего HTML. Только смысловой контент. Но честно → так происходит не всегда, особенно при сложном парсинге карточек товара на маркетплейсах. Порой огненный кроулер в напаршенных данных выдает всякого дополнительного мусора, но как раз таки LLM системы, если им указать тип мусора, могут эффективно игнорировать его при работе с данными.
Компания основана в 2022 году под названием SideGuide Technologies, прошла акселератор Y Combinator. В августе 2025 года привлекла $14,5 млн инвестиций в раунде серии A. Среди клиентов — OpenAI, Shopify, Replit и Alibaba. К моменту раунда на платформе было зарегистрировано более 350 000 разработчиков.
Данные по финансированию и числу пользователей основаны на суммарном интернет-контексте по топ-20 изданиям в нише, полученному с помощью системы Perplexity, а также открытым публикациям компании.
Как работает Firecrawl изнутри
Firecrawl принципиально отличается от традиционных парсеров. Старые инструменты просто «считывали» HTML-код страницы — со всем мусором: рекламными баннерами, меню, подвалами и скриптами. Firecrawl применяет ИИ-модели, которые понимают содержание и структуру страницы, фильтруют лишнее и возвращают только смысловой контент.
Ключевой принцип — нулевой селектор (zero-selector). Традиционный парсинг требовал знания CSS-селекторов и XPath (технические адреса элементов на странице). В Firecrawl вы просто описываете задачу на естественном языке: «извлеки название товара, цену и описание» — и ИИ сам разберётся.
Технически сервис работает через единый REST API (стандартный веб-интерфейс для программ). Он умеет рендерить (загружать и исполнять) JavaScript — то есть берёт данные даже с современными React/Vue/Angular сайтами сделаными вайбкод стэком, где контент подгружается динамически.
Полный арсенал возможностей: что умеет делать
Firecrawl — это не просто «загрузить страницу». Это целый набор инструментов для работы с веб-данными:

Дополнительные возможности
- Обход бот-защит — встроенный механизм Fire-engine (доступен в облаке) помогает обходить базовые защиты сайтов
- Рендеринг JavaScript — берёт контент с динамических SPA-приложений (React, Vue, Angular)
- Парсинг PDF и DOCX — умеет читать документы, не только веб-страницы
- Скриншоты страниц — сохраняет визуальное представление
- Поддержка авторизации — может работать с сайтами, требующими логина
- Взаимодействие с элементами — умеет кликать, скроллить, заполнять формы
- MCP-сервер (Model Context Protocol) — прямая интеграция с ИИ-агентами через стандартный протокол
Форматы вывода
Firecrawl возвращает данные в любом удобном формате: Markdown, HTML, JSON, метаданные, скриншоты.
Кому нужен Firecrawl и для каких задач
Firecrawl — прежде всего инструмент для разработчиков и технических специалистов. Без базовых знаний API и хотя бы минимального понимания программирования работать с ним затруднительно. Что такое API читайте в нашей статье.
Целевая аудитория
ИИ-разработчики и инженеры данных:
- Построение RAG-пайплайнов (Retrieval-Augmented Generation — дополнение ИИ актуальными данными из интернета)
- Создание баз знаний для чат-ботов с актуальной документацией
- Обучение и тонкая настройка LLM на свежих веб-данных
- Построение ИИ-агентов, которые исследуют интернет самостоятельно
Маркетологи и аналитики (с техническим бэкграундом или в связке с разработчиком):
- Конкурентная разведка: автоматический сбор данных с сайтов конкурентов
- SEO-аудит: анализ структуры и контента сайтов
- Мониторинг цен в e-commerce
- Генерация лидов через парсинг бизнес-директорий
Продуктовые команды и стартапы:
- Создание альтернативных поисковиков типа Perplexity
- Построение дашбордов с мониторингом рынка
- Автоматизация исследовательских процессов
Конкретные примеры задач
- Собрать документацию конкурента и загрузить в базу знаний ИИ-ассистента
- Ежедневно парсить 500 карточек товаров со сравнением цен
- Автоматически собирать отзывы о продукте с разных площадок
- Создать систему мониторинга упоминаний бренда в интернете
- Построить «умный» новостной агрегатор с суммаризацией
- Спарсить страницу и на основании ее данных затем сгенерировать пост, видео или карусель контента.
Как начать: пошаговая инструкция
Начать работу с Firecrawl можно за 15–20 минут.
Шаг 1: Регистрация
Перейдите на firecrawl.dev и создайте аккаунт. Банковская карта для бесплатного тарифа не нужна.
Шаг 2: Получите API-ключ
После регистрации в личном кабинете получите API-ключ — уникальный токен доступа к сервису.
Шаг 3: Первый тест через curl или документацию
Самый простой запрос — scrape одной страницы:
Шаг 4: Интеграция с вашим инструментом
Firecrawl поддерживает SDK (готовые библиотеки) для Python и JavaScript/TypeScript. Устанавливается одной командой:
Шаг 5: Подключение к ИИ-фреймворку
Firecrawl имеет готовые интеграции с: LangChain, LlamaIndex, CrewAI, Dify, Flowise, AutoGPT и другими популярными фреймворками для ИИ.
Для тестирования Firecrawl CLI (консольного интерфейса) потребуется Node.js. Установка: npm install -g firecrawl-cli. Команда firecrawl scrape https://example.com сразу вернёт вам Markdown-версию страницы.
Тарифы и реальная стоимость
Это самый важный раздел, если вы планируете использовать Firecrawl в продакшене. Система ценообразования здесь неочевидная.
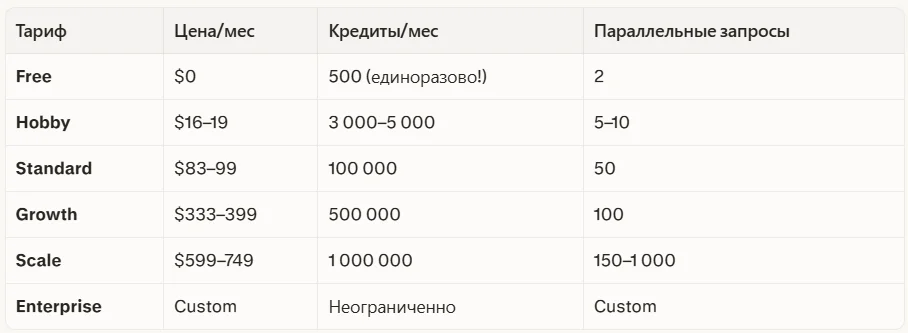
Цены варьируются при оплате помесячно или за год (при годовой оплате скидка около 20%).
Важный нюанс №1: 500 бесплатных кредитов — это НЕ ежемесячно
Многие пользователи узнают об этом слишком поздно. Бесплатные 500 кредитов выдаются один раз на весь аккаунт — не каждый месяц. После их использования нужно переходить на платный тариф.
Важный нюанс №2: двойная система оплаты
Если вам нужна функция Extract (структурированное извлечение данных через ИИ) — это отдельная подписка, которая добавляется к основному плану:
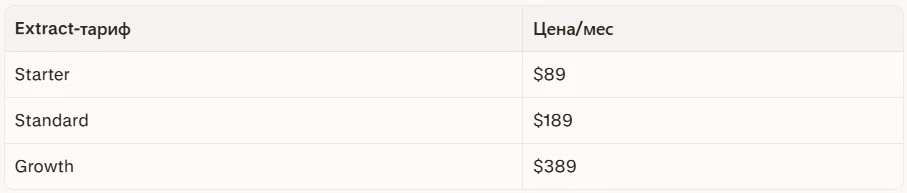
То есть пользователь на тарифе Standard ($99) + Extract Starter ($89) платит фактически $188/мес.
Важный нюанс №3: мультипликаторы кредитов
Базовая ставка «1 кредит за страницу» работает только для простого скрейпинга. В реальности:
- Базовый Scrape/Crawl: 1 кредит/страница
- JSON-извлечение: +4 кредита (итого 5x)
- Enhanced Mode: +4 кредита
- JSON + Enhanced Mode: до 9 кредитов за страницу
- Режим Agent: 100–1500+ кредитов за запрос
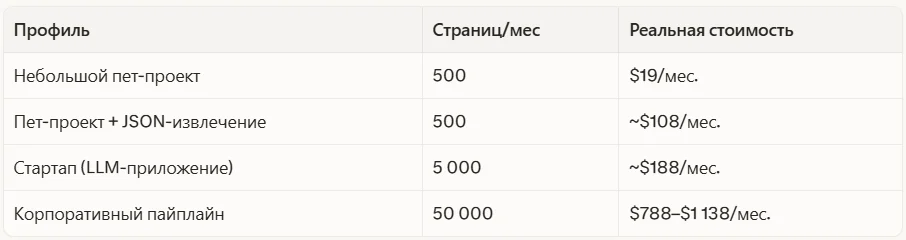
Кредиты не переносятся на следующий месяц. Неудачные запросы тоже списываются (потери до 20–30% на нестабильных сайтах).
Firecrawl vs аналоги сравнение
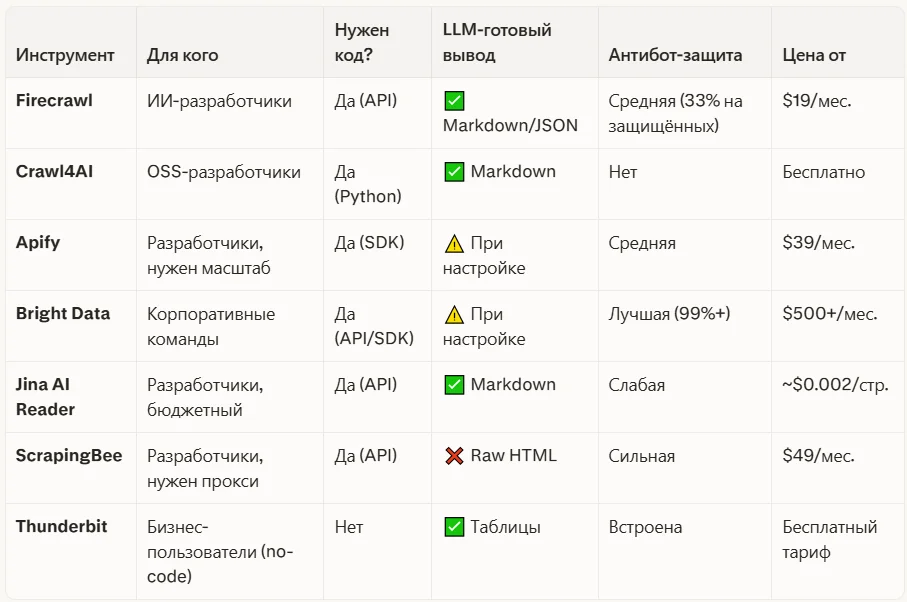
- Качество Markdown-вывода для LLM — одно из лучших на рынке
- Нулевые усилия по инфраструктуре — облако сделает всё само
- Ширина интеграций с ИИ-фреймворками (7+ готовых коннекторов)
- MCP-сервер для прямой интеграции с ИИ-агентами
- Скорость картографирования сайта (Map — до 100K URL за секунды)
Где Firecrawl проигрывает:
Независимый бенчмарк агентства Proxyway по 15 сайтам с сильной бот-защитой показал: Firecrawl достиг лишь 33,69% успешности — последнее место среди 10 провайдеров. Для сравнения, Zyte — 93%, Bright Data — 88%.
На сайтах без сильной защиты (блоги, документация, SaaS-лендинги) — 85–98% успешности. На Amazon, LinkedIn, сайтах с Cloudflare или карточках маркетплейсов — нестабилен.
Чем Firecrawl помогает маркетологу
Маркетолог без команды разработчиков может использовать Firecrawl через готовые интеграции — или поставить задачу техническому специалисту. Вот реальные кейсы применения:
1. Конкурентная разведка на автопилоте
Настраиваете краулинг сайтов конкурентов раз в неделю — и получаете структурированные данные: новые страницы, изменения в ценах, появление новых продуктов. Загружаете всё в ChatGPT или Claude — и просите сделать сравнительный анализ.
Это на порядок быстрее, чем ручной мониторинг. Если вы пока не знакомы с тем, как использовать ИИ для конкурентного анализа, полезно прочитать: Промпт для конкурентного анализа в Perplexity.
2. Построение базы знаний для ИИ-продавца или чат-бота
Вы хотите, чтобы ваш ИИ-ассистент знал всё о вашем продукте, отвечал на вопросы клиентов и закрывал возражения. Firecrawl позволяет буквально «скормить» ему весь ваш сайт: краулинг → чистый текст → загрузка в базу знаний LLM.
Если вы уже работаете или планируете запустить ИИ-продавца для бизнеса, посмотрите сервис NeuroAgents — там уже встроены инструменты для подключения внешних баз знаний и интеграций.
3. SEO и GEO-аудит сайтов
Firecrawl позволяет выгрузить полную карту любого сайта (тысячи URL за секунды), получить текстовое содержимое каждой страницы и проанализировать структуру. Это ценно для GEO-продвижения — понимания, как ИИ-поисковики воспринимают ваш контент и для дополнения своей SEO/ИИ-трафик стратегии.
4. Генерация лидов через парсинг каталогов
Парсинг бизнес-каталогов, профилей компаний, агрегаторов объявлений — и получение структурированного списка потенциальных клиентов с контактами, описанием деятельности и размером бизнеса. Это сырьё для лидогенерации на автопилоте.
5. Мониторинг упоминаний и репутация
Настроив регулярный обход тематических форумов, отзовиков и СМИ — вы получаете актуальный срез того, что говорят о вас или вашей нише в реальном времени.
Полезный промпт для ИИ: конкурентный анализ через Firecrawl
Если у вас есть техническая возможность использовать Firecrawl API или вы работаете с разработчиком — этот промпт поможет настроить глубокий анализ конкурентов. Скопируйте его и запустите в любой из систем: ChatGPT, Claude, Gemini, Алиса от Яндекса или в агрегаторе нейросетей SYNTX.AI — там в одном месте доступны ChatGPT, Claude, Gemini, Midjourney, Sora, Kling и 100+ других ИИ без VPN, с оплатой в рублях.
ПРОМПТ: Анализ конкурентов с помощью Firecrawl
Я собираю данные с сайтов конкурентов через Firecrawl API и хочу провести глубокий конкурентный анализ.
Вот краулинговые данные с сайта конкурента (вставь Markdown-вывод из Firecrawl): [ВСТАВЬ ДАННЫЕ]
Моя ниша: [укажи нишу] Мой продукт: [опиши продукт]
Проанализируй по следующим блокам:
- ПРОДУКТОВАЯ ЛИНЕЙКА — Какие продукты/услуги они предлагают? — Как сформулированы оффер и ценностное предложение? — Какие опции, тарифы, пакеты есть?
- МАРКЕТИНГОВЫЕ СМЫСЛЫ — Какие ключевые боли и желания ЦА они закрывают? — Какие триггеры доверия используют (кейсы, цифры, отзывы)? — Какой CTA (призыв к действию) используется?
- SEO И СТРУКТУРА — Какие темы/ключевые слова покрывает их контент? — Какова структура сайта?
- СЛАБЫЕ МЕСТА КОНКУРЕНТА — Что они упускают или делают слабо? — Где есть пространство для нашего дифференцирования?
- ВЫВОДЫ ДЛЯ НАШЕЙ СТРАТЕГИИ — Что конкретно мы можем применить? — Чего делать НЕ стоит?
Дай структурированный отчёт с конкретными цитатами из их контента в качестве доказательств.
Типичные ошибки при работе с Firecrawl
Пользователи регулярно допускают одни и те же ошибки. Вот как их избежать:
Ошибка 1: Не читают условия бесплатного тарифа
500 кредитов — единоразово, не ежемесячно. Они заканчиваются после первого же массового теста. Планируйте бюджет заранее.
Ошибка 2: Игнорируют мультипликаторы кредитов
Включив JSON-извлечение + Enhanced Mode, вы тратите до 9 кредитов на страницу вместо 1. На масштабе это разница в 9x по счёту.
Ошибка 3: Пытаются парсить сильно защищённые сайты
Amazon, LinkedIn, сайты на Cloudflare — Firecrawl справляется с ними лишь в 33% случаев. Для таких задач нужны специализированные решения.
Ошибка 4: Рассчитывают на полноценный self-hosting
Open-source версия не включает режим Agent, антибот-движок Fire-engine, Browser Sandbox и пакетную обработку. Для продакшена нужен облачный тариф.
Ошибка 5: Используют режим Agent без ограничения кредитов
Один запрос к Agent может стоить 200–1500+ кредитов. Всегда устанавливайте параметр maxCredits.
FAQ
Что такое Firecrawl простыми словами?
Это сервис, который умеет читать любой сайт и превращать его содержимое в чистый текст или структурированные данные. Представьте: вы хотите, чтобы ваш ИИ-ассистент знал всё о конкурентах — Firecrawl «скармливает» ему нужные сайты в понятном формате.
Нужно ли уметь программировать для работы с Firecrawl?
Да, базовые знания необходимы. Firecrawl — это API-инструмент, работа с которым требует умения делать HTTP-запросы и разбираться в JSON. Если вы нетехнический специалист, рассмотрите no-code альтернативы: Thunderbit или Apify с визуальным интерфейсом.
Сколько стоит Firecrawl для небольшого проекта?
Если вам нужен только базовый краулинг без Extract — тариф Hobby за $16–19/мес. покроет до 5 000 страниц. Если нужно структурированное извлечение — добавьте минимум $89/мес. за Extract.
Можно ли использовать Firecrawl бесплатно постоянно?
Нет. Бесплатный тариф даёт 500 кредитов один раз. Для регулярного использования нужен платный план. Open-source версия доступна, но без ключевых облачных функций.
Как Firecrawl обходит защиту от ботов?
В облачной версии есть встроенный движок Fire-engine. Однако на сильно защищённых сайтах (Cloudflare, крупный e-commerce) эффективность низкая — около 33% по независимым бенчмаркам.
Какие ИИ-фреймворки поддерживает Firecrawl?
LangChain, LlamaIndex, CrewAI, Dify, Flowise, AutoGPT и ещё ряд популярных решений. Также есть официальный MCP-сервер для интеграции с ИИ-агентами через стандартный протокол.
Чем Firecrawl отличается от обычного парсера?
Обычный парсер возвращает сырой HTML со всем мусором. Firecrawl применяет ИИ-модели, которые понимают структуру и смысл страницы, фильтруют лишнее и возвращают чистый контент, готовый для LLM.
Можно ли использовать Firecrawl для создания ИИ-агентов?
Да, это один из ключевых сценариев. Функция Agent позволяет запустить автономного исследователя, который сам ищет нужную информацию в интернете. Для глубокого погружения в тему ИИ-агентов читайте: ИИ-агенты: руководство для бизнеса 2026.
Вывод
Firecrawl — это мощный инструмент для тех, кто строит ИИ-продукты, базы знаний или системы конкурентного мониторинга. Его главное преимущество — качество LLM-готовых данных и богатая экосистема интеграций. Главная ловушка — непрозрачная система кредитов, которая может удвоить реальный счёт.
А если вы хотите запустить собственного ИИ-агента или ИИ-продавца для вашего бизнеса — попробуйте сервис NeuroAgents. Там уже есть всё необходимое для старта: от готовых шаблонов до интеграций с мессенджерами и CRM.