Содержание
- Что такое Gemma 4 и откуда она взялась
- Все четыре модели семейства: от Raspberry Pi до рабочей станции
- 7 ключевых фишек, которые меняют правила игры
- Архитектура: почему Gemma 4 такая быстрая и умная
- Бенчмарки: как Gemma 4 бьёт конкурентов в 20 раз крупнее
- Gemma 4 vs ChatGPT, Claude, Llama — честное сравнение
- Плюсы и минусы Gemma 4
- Как запустить Gemma 4 бесплатно локально — пошагово
- Как бизнесу и маркетологу применять Gemma 4 прямо сейчас
- Экономика: когда Gemma 4 выгоднее облачных API
- Промпт для работы с Gemma 4 в вашем бизнесе
- FAQ: частые вопросы о Gemma 4
Что такое Gemma 4 и откуда она взялась
Gemma 4 — это семейство открытых мультимодальных языковых моделей (LLM, Large Language Model) от Google DeepMind, выпущенных 2 апреля 2026 года под лицензией Apache 2.0. Говоря простым языком: это нейросеть, которую можно скачать, запустить на своём компьютере и использовать в коммерческих проектах совершенно бесплатно.
Название «Gemma» происходит от латинского слова «gemma» — драгоценный камень. Gemma — «младшая сестра» закрытой нейросети Google Gemini (которая работает в Google так же, как ChatGPT работает в OpenAI). Разница принципиальная: Gemini — закрытая коммерческая модель, а Gemma — полностью открытая, с публичными весами (weights — числовые параметры, которые определяют поведение модели).
Разрабатывает Gemma команда Google DeepMind — одна из сильнейших ИИ-лабораторий мира, ответственная за такие прорывы, как AlphaFold и Gemini Ultra.
История серии и почему Gemma 4 — это прорыв
Google выпустила первую Gemma в начале 2024 года. С тех пор разработчики скачали модели серии более 400 миллионов раз и создали свыше 100 000 вариантов (fine-tuned версий под конкретные задачи). Это гигантское сообщество — Google называет его Gemmaverse.
С каждым поколением прыжок был заметным, но Gemma 4 — это особый случай. Несколько цифр, которые говорят сами за себя:
- Результат на математическом тесте AIME 2026: с 20.8% до 89.2% (+68 процентных пунктов)
- Результат на тесте программирования LiveCodeBench: с 29.1% до 80.0% (+50.9 п.п.)
- Рейтинг Arena AI: 3-е место в мире среди открытых моделей
(Данные по бенчмаркам взяты из анализа топ-20 технических изданий в нише, агрегированного через Perplexity, а также из официальной документации Google DeepMind.)
Все четыре модели семейства: от Raspberry Pi до рабочей станции
Google выпустила Gemma 4 сразу в четырёх размерах — под любое железо и задачу.
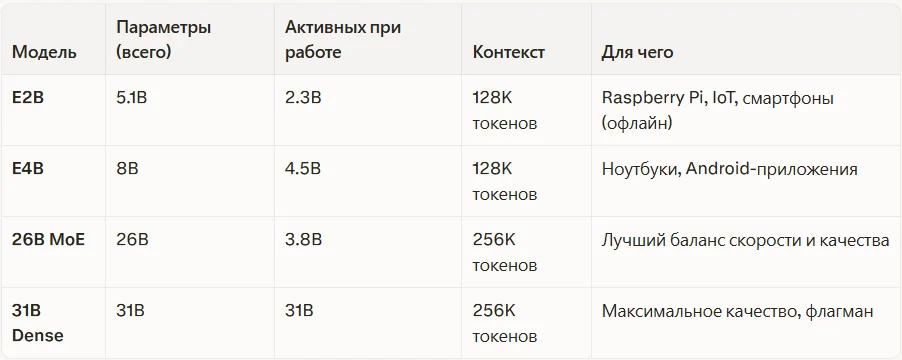
E2B и E4B — нейросеть прямо на телефоне
Буква «E» в названии означает Effective (эффективный). Эти модели спроектированы с нуля под мобильные устройства: они работают полностью офлайн, без задержки сети, с минимальным расходом батареи. E2B запускается даже на Raspberry Pi и NVIDIA Jetson Nano.
26B MoE — самая умная архитектурная хитрость
MoE расшифровывается как Mixture of Experts (смесь экспертов). Представьте офис: когда приходит задача по финансам — её решает финансист, по праву — юрист. Не все 100 сотрудников участвуют в каждой задаче. Так же работает эта модель: из 26 миллиардов параметров при каждом запросе активируется только 3.8 миллиарда.
31B Dense — когда нужен максимум
Все 31 миллиард параметров работают постоянно. Это максимальное качество, которое Google может предложить в открытом формате на сегодняшний день — 3-е место в мировом рейтинге Arena AI.
7 ключевых фишек, которые меняют правила игры
1. Режим глубокого мышления (Chain-of-Thought)
Chain-of-Thought (цепочка мышления) — режим, в котором модель «думает вслух» перед ответом, выстраивая шаги рассуждений, как человек при решении сложной задачи. Этот режим можно включать и выключать: для быстрых ответов — выключаем, для сложной математики или анализа — включаем. Именно он обеспечил скачок с 20% до 89% на математических тестах.
2. Полная мультимодальность из коробки
Мультимодальность — способность модели работать не только с текстом, но и с другими форматами данных. Все модели Gemma 4, кроме самых маленьких, работают с изображениями, видео и аудио без дополнительной настройки:
- Изображения: распознавание объектов, OCR (оптическое распознавание текста на сканах), понимание графиков и схем, парсинг PDF
- Видео: анализ содержимого, ответы на вопросы о конкретных моментах
- Аудио (E2B/E4B): распознавание речи, перевод в реальном времени
- GUI (графический интерфейс): понимает скриншоты приложений — модель буквально «видит» экран
3. Нативная поддержка ИИ-агентов
Function calling (вызов функций) — встроенная способность модели обращаться к внешним инструментам и API (программным интерфейсам). На базе Gemma 4 можно строить автономных ИИ-агентов, которые ищут информацию в интернете, обращаются к базам данных и выполняют многошаговые задачи без участия человека.
Если вас интересует тема ИИ-агентов для бизнеса — читайте подробный материал: ИИ-агенты, нейросотрудники и ИИ-ассистенты: руководство для бизнеса 2026.
4. Огромное контекстное окно — 256K токенов
Контекстное окно — это «оперативная память» нейросети, сколько текста она удерживает в голове одновременно. 256K токенов — это примерно 500 страниц текста. Загрузите целую книгу, всю переписку с клиентом или большой кодовый репозиторий — модель всё «запомнит» и будет работать с этим массивом данных.
5. 140+ языков, включая русский
Gemma 4 обучена на более чем 140 языках. Качество русского языка значительно улучшено по сравнению с Gemma 3. Модель хорошо справляется с генерацией текста, переводами и ответами на вопросы на русском языке без дополнительного дообучения.
6. Полностью свободная лицензия Apache 2.0
Apache 2.0 означает: берёшь модель, встраиваешь в свой продукт, дообучаешь на своих данных, продаёшь — всё легально и бесплатно. В отличие от конкурента Llama (у Meta, компания признана в РФ экстремистской и запрещена), у Gemma 4 нет ограничений по количеству пользователей или доходу.
7. Работает полностью локально и офлайн
Ваши данные никуда не уходят. Модель работает на вашем сервере или ноутбуке — без облака, без API, без абонентской платы. Для бизнеса, работающего с конфиденциальными данными клиентов, это критически важное преимущество.
Архитектура: почему Gemma 4 такая быстрая и умная
Технически подкованным читателям будет интересно: Google применила несколько нетривиальных архитектурных решений.
Alternating Attention (чередующееся внимание) — модель чередует два типа обработки контекста: быстрый «локальный» (анализирует ближайший текст) и «глобальный» (анализирует весь документ). Это позволяет обрабатывать огромные тексты без квадратичного роста вычислительной нагрузки.
Dual RoPE (двойное позиционное кодирование) — два разных механизма, которые говорят модели «где ты находишься в тексте»: один для коротких фрагментов, другой для длинных документов. В результате качество не падает даже на текстах в 256K токенов.
Per-Layer Embeddings (встраивания на уровне слоёв) — каждый слой модели получает дополнительную информацию о токенах. Улучшает качество без увеличения размера модели.
Shared KV Cache (общий кэш ключей и значений) — оптимизация памяти, позволяющая быстрее генерировать текст при большом контексте.
Бенчмарки: как Gemma 4 бьёт конкурентов в 20 раз крупнее
Вот результаты флагманской 31B-модели на стандартных тестах:
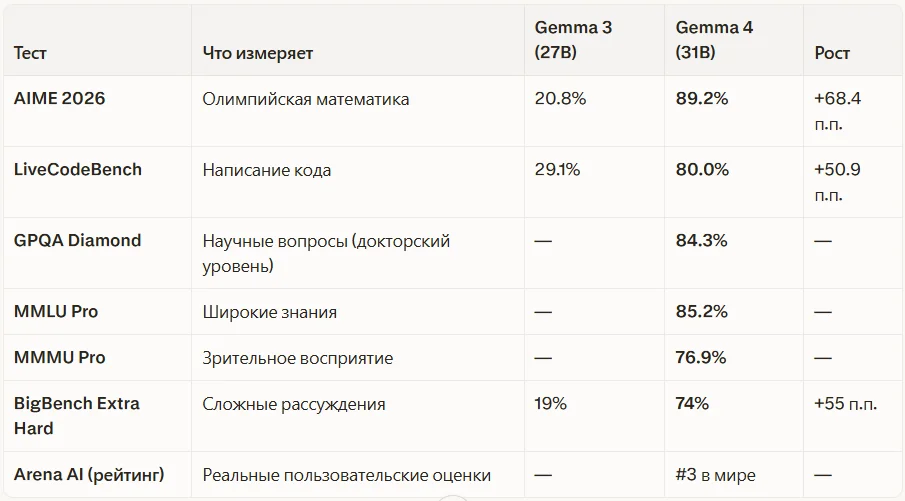
Скачок по математике с 20.8% до 89.2% — это не эволюция, а смена поколений. Такой прогресс стал возможен благодаря режиму chain-of-thought мышления.
Gemma 4 vs ChatGPT, Claude, Llama — честное сравнение
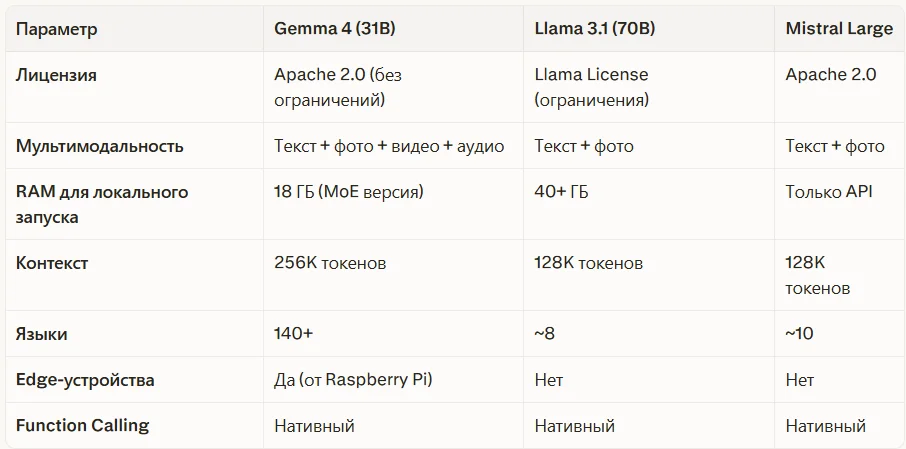
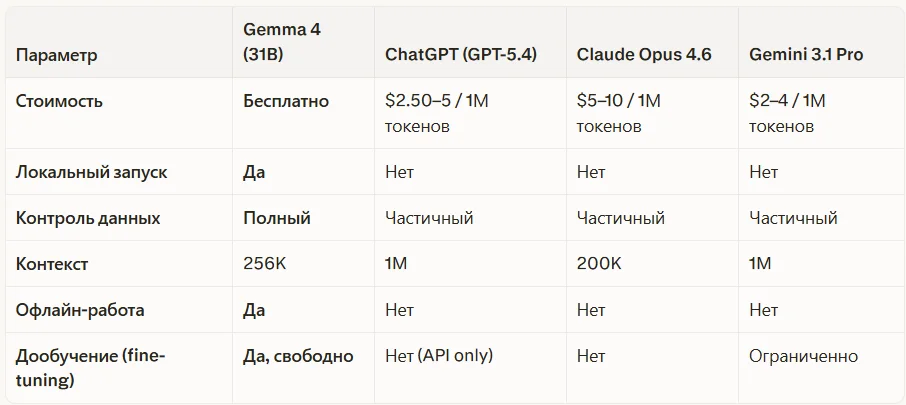
О том, как устроены и чем отличаются ведущие закрытые нейросети, читайте в наших разборах: ChatGPT — полный гайд 2026 и Claude — полный гайд 2026. А если интересует тема открытых нейросетей в целом — смотрите наш обзор: Открытые нейросети 2026: что это, чем отличаются от закрытых и почему весь мир на них переходит.
Плюсы и минусы Gemma 4
Плюсы
- Полностью бесплатна — Apache 2.0, нет лицензионных платежей, нет подписки
- Локальный запуск — данные не покидают ваш сервер или устройство
- Лучшая эффективность параметров — 31B обгоняет модели в 20 раз крупнее
- Нативная мультимодальность — текст, фото, видео, аудио из коробки
- Edge-версии — работает на смартфонах и одноплатных компьютерах офлайн
- Режим цепочки мышления — chain-of-thought для сложных задач
- 256K токенов контекста — эквивалент 500 страниц текста
- 140+ языков, включая русский
- Гигантская экосистема — поддержка Ollama, Hugging Face, LM Studio, vLLM и десятков других инструментов
- Дообучение под нишу — можно специализировать модель под свои данные
Минусы и ограничения
- Требует железо — для 31B Dense нужно минимум 24 ГБ VRAM; для 26B MoE — 18 ГБ. Облачные API дешевле для старта без мощного компьютера
- Уступает гигантам в сложных задачах — GPT-5.4 и Claude Opus 4.6 сильнее в глубоком долгосрочном рассуждении и работе с документами свыше 200K токенов
- Нет встроенного поиска в интернете — в базовой версии модель не имеет доступа к актуальным данным; нужна дополнительная интеграция с поисковыми инструментами
- Нет готового интерфейса — в отличие от ChatGPT или Claude, Gemma 4 это только модель, а не готовый продукт со встроенным UI (интерфейсом пользователя); нужно ставить Ollama, LM Studio или аналоги
- Сложность тонкой настройки — локальный запуск несложен, но глубокая интеграция в бизнес-системы требует технических знаний или специалиста
Как запустить Gemma 4 бесплатно локально — пошагово
Самый простой путь — через Ollama (программа-менеджер локальных нейросетей). Работает на macOS, Linux и Windows.
Шаг 1: Установите Ollama
Скачайте и установите с сайта ollama.com. На macOS/Linux — команда в терминале:
Шаг 2: Скачайте нужную версию Gemma 4
ollama pull gemma4
# Компактная версия (4B — для ноутбука с 8 ГБ RAM)
ollama pull gemma4:4b
# Флагман (31B Dense — максимальное качество, ~24 ГБ VRAM)
ollama pull gemma4:31b
Шаг 3: Запустите чат
Всё. Через несколько минут у вас работающая нейросеть на вашем компьютере.
Альтернативные способы запуска
- LM Studio — графический интерфейс без командной строки: скачайте с lmstudio.ai, найдите «gemma 4», нажмите Download. Подходит, если терминал вас пугает.
- Google AI Studio (aistudio.google.com) — онлайн-интерфейс от Google для тестирования 31B и 26B MoE без установки, с бесплатным тарифом.
- Hugging Face — скачать веса для разработки на Python через библиотеку
transformers.
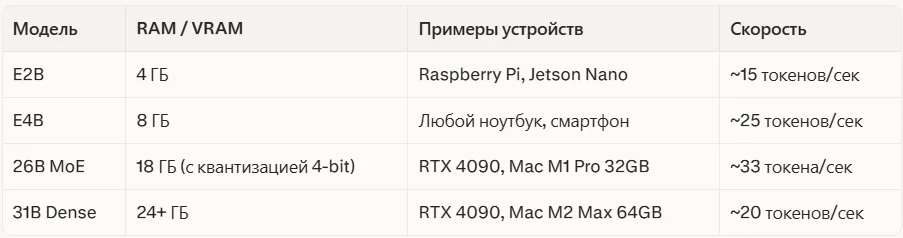
Требования к железу
Как бизнесу и маркетологу применять Gemma 4 прямо сейчас
Gemma 4 — это не просто «умный чат». Это инфраструктурный инструмент для бизнеса. Вот конкретные применения:
Корпоративный ассистент с конфиденциальными данными. Дообучите (fine-tune) модель на внутренних документах компании — регламентах, кейсах, скриптах продаж. Модель будет работать только на вашем сервере, без передачи данных третьим лицам.
Автоматизация работы с документами. Загрузите договор, акт или коммерческое предложение — 256K токенов позволяют работать с документами объёмом до 500 страниц. Модель распознает текст, извлечёт ключевые условия и ответит на вопросы.
Мобильные приложения с ИИ без облака. Если вы разрабатываете Android-приложение — E4B позволяет встроить ИИ, который работает полностью офлайн: в метро, на даче, в зоне без связи.
Локальный кодинг-ассистент. На базе 26B MoE можно поднять полноценный AI-помощник для программиста, работающий прямо в IDE (среде разработки) — без утечки кода в облако. Кстати, если тема кодинга с ИИ вам интересна, обратите внимание на Claude Code — ещё один мощный инструмент для разработки.
Вайбкодинг и создание сайтов без программиста. Gemma 4 отлично встраивается в пайплайны вайбкодинга — подхода, при котором сайты и приложения создаются голосовыми или текстовыми командами. Подробнее об этом тренде: Вайбкодинг (Vibe Coding): что это такое и почему весь мир кодит «по вайбу» в 2026 году.
ИИ-агенты для автоматизации процессов. Function calling позволяет строить цепочки автоматических действий: модель сама решает, какой инструмент вызвать, в каком порядке выполнить шаги. Подробнее об этом направлении: ИИ-агенты, нейросотрудники и ИИ-ассистенты.
Экономика: когда Gemma 4 выгоднее облачных API
Посчитаем на простом примере. Команда из 5 человек тратит 50 000 ₽ в месяц на ChatGPT и Claude API. Видеокарта RTX 4090 стоит около 200 000 ₽. При запуске 26B MoE Gemma 4 на этой карте затраты на API становятся равны нулю — окупаемость составит 4 месяца.
Для малого и среднего бизнеса, где есть хотя бы один технический специалист, это честная арифметика. Для стартапов с чувствительными данными (медицина, юриспруденция, финансы) — это ещё и снятие рисков утечки данных клиентов.
Промпт для работы с Gemma 4 в вашем бизнесе
Где запустить этот промпт:
- Через Ollama на своём компьютере командой
ollama run gemma4
- В Google AI Studio (aistudio.google.com) — онлайн, бесплатно
Твоя область: [ВАША НИША, например: digital-маркетинг / e-commerce / строительство]
ЗАДАЧА: Помоги мне с [КОНКРЕТНАЯ ЗАДАЧА, например: написать коммерческое предложение / проанализировать текст договора / составить скрипт переговоров].
КОНТЕКСТ:
- Моя целевая аудитория: [ОПИШИТЕ ЦА]
- Мой продукт/услуга: [ОПИСАНИЕ]
- Ключевые преимущества: [1–3 УТП]
- Возражения, которые часто слышу от клиентов: [ПЕРЕЧИСЛИТЕ]
ФОРМАТ ОТВЕТА:
- Дай структурированный ответ с разбивкой по разделам
- Используй конкретные формулировки, не общие фразы
- Предложи 2–3 варианта, если задача предполагает несколько подходов
- Язык: русский, деловой, живой — без канцелярита
Начни с краткого резюме (2–3 предложения), затем перейди к основному содержанию.
Как запустить: смотрите раздел «Как запустить Gemma 4 бесплатно локально» выше — там пошаговая инструкция через Ollama за 5 минут.
Если эта статья была полезной — вам понравится Телеграм-канал Дмитрия Борейчука, основателя Wake Up Marketing: практика в маркетинге и ИИ с 11-летним опытом, разборы свежих нейросетей, кейсы внедрения и бесплатные обучения.
FAQ: частые вопросы о Gemma 4
Что такое Gemma 4 простыми словами?
Gemma 4 — это мощная нейросеть от Google, которую можно скачать и запустить на своём компьютере или смартфоне бесплатно. Она понимает текст, изображения, видео и аудио, поддерживает русский язык и может использоваться в коммерческих проектах без ограничений.
Gemma 4 бесплатная или платная?
Полностью бесплатная под лицензией Apache 2.0. Можно скачать, запустить локально, встроить в продукт, дообучить на своих данных и продавать решения на её основе. Никаких платежей, подписок и ограничений по пользователям или доходу.
Чем Gemma 4 отличается от Gemma 3?
Три ключевых отличия: 1) Лицензия Apache 2.0 вместо ограничивающей Gemma Open License. 2) Встроенный режим chain-of-thought мышления — резкий скачок в математике и программировании. 3) Нативная поддержка видео и аудио, архитектура MoE для 26B-версии.
Может ли Gemma 4 заменить ChatGPT?
В задачах с конфиденциальными данными, локальной автоматизации и edge-приложениях — да. В сложных аналитических задачах, требующих максимальной точности, GPT-5.4 и Claude Opus 4.6 пока сильнее. Главное преимущество Gemma 4 — она бесплатная и работает локально.
На каком железе запустить Gemma 4?
Зависит от версии: E4B (4B) — любой ноутбук с 8 ГБ RAM; 26B MoE — видеокарта с 18 ГБ VRAM или Mac с 32 ГБ; 31B Dense — минимум 24 ГБ VRAM. Самая маленькая версия E2B работает даже на Raspberry Pi.
Как хорошо Gemma 4 понимает и пишет по-русски?
Gemma 4 обучена на 140+ языках, включая русский. Качество существенно улучшено по сравнению с Gemma 3 — модель хорошо пишет, переводит и отвечает на вопросы на русском языке без дополнительного дообучения.
Можно ли дообучить Gemma 4 на своих данных?
Да, лицензия Apache 2.0 это разрешает. Дообучение (fine-tuning) позволяет специализировать модель под конкретную нишу: медицину, право, ваш продукт. Поддерживаются платформы Vertex AI, Google Colab, Unsloth и другие.
Как встроить Gemma 4 в мобильное приложение?
Через Google ML Kit GenAI Prompt API или AICore Developer Preview для Android. Модели E2B и E4B оптимизированы для работы на смартфонах полностью офлайн — без интернета и без задержки облака.
# Оптимальная версия (26B MoE — баланс скорости и качества, ~18 ГБ RAM)
ollama pull gemma4
# Компактная версия (4B — для ноутбука с 8 ГБ RAM)
ollama pull gemma4:4b
# Флагман (31B Dense — максимальное качество, ~24 ГБ VRAM)
ollama pull gemma4:31b