Содержание
- Что такое открытые нейросети и как они работают
- Открытые vs закрытые модели: ключевые отличия
- Почему open source набирает силу именно в 2026 году
- Топ открытых нейросетей 2026: Llama 4, DeepSeek V4, Gemma 4 и другие
- Риски и ограничения: о чём молчат энтузиасты
- Как бизнес применяет открытые модели прямо сейчас
- Готовый промпт для анализа открытых нейросетей под вашу задачу
- FAQ: частые вопросы об open source нейросетях
Что такое открытые нейросети и как они работают
Открытая нейросеть — это языковая модель, веса и (часто) исходный код которой разработчики публикуют в открытый доступ. Это значит: любой человек может скачать модель, запустить её на своём сервере и изменять под себя без разрешения компании-создателя.
Для понимания аналогия: закрытая нейросеть — это продукт типа iPhone, где Apple контролирует каждую деталь. Открытая нейросеть — это Linux: берёшь, ставишь, переписываешь под свои нужды.
Технически любая нейросеть — это математическая модель, обученная на огромных массивах текста. Её «мозг» — веса (weights): числовые коэффициенты, которые накапливаются в процессе обучения и определяют, как модель отвечает на запросы. Именно эти веса открытые компании публикуют на платформах вроде Hugging Face, GitHub или Ollama.
Открытые vs закрытые модели: ключевые отличия
Это не просто разница в цене. Речь идёт о принципиально разных подходах к ИИ.
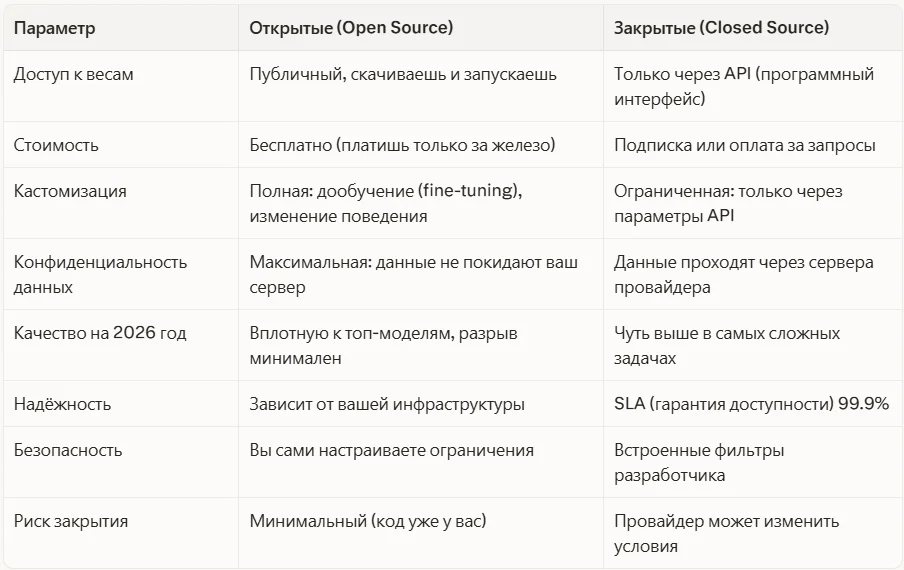
Ключевой вопрос выбора — зачем вам нейросеть. Для быстрого старта и сложных задач (генерация контента, агентные системы) удобнее закрытые API. Для работы с чувствительными данными клиентов, серьезной кастомизации под нишу или снижения затрат при больших объёмах запросов — открытые модели становятся очевидным выбором.
Почему open source набирает силу именно в 2026 году
Ещё два года назад открытые модели заметно уступали GPT и Claude. Сегодня разрыв сократился до минимума. Этому способствовали три ключевых фактора.
1. Технологический прорыв: архитектура MoE
Большинство топовых открытых моделей 2026 года используют архитектуру Mixture of Experts (MoE) — «смесь экспертов». Суть: модель содержит сотни специализированных «экспертных» подсетей, но при каждом запросе активирует лишь несколько из них. Это позволяет иметь гигантский суммарный объём знаний при низких затратах на обработку каждого запроса.
2. Экономический стимул
DeepSeek V3 показал, что обучить модель класса GPT-4 можно с затратами, на 97% меньшими, чем у OpenAI. Это обрушило прежний аргумент «открытые не могут быть такими же умными, потому что нет денег на обучение».
3. Регуляторное давление и суверенитет данных
В марте 2026 года Минцифры России предложило законопроект, ограничивающий использование иностранных ИИ-систем для государственных структур. Открытые модели — Qwen, DeepSeek — можно разворачивать локально, что делает их соответствующими требованиям. Аналогичные тренды на «цифровой суверенитет» наблюдаются в Европе и Азии.
4. Экосистема инструментов выросла
Вокруг открытых моделей сложилась зрелая экосистема: RAG-фреймворки (системы поиска по своим документам), платформы для дообучения, агентские среды. Теперь не нужно быть ML-инженером, чтобы развернуть локальный ИИ.
Топ открытых нейросетей 2026 года
Llama 4 от Meta*
Meta* (*компания Meta, которой принадлежит Instagram, признана в России экстремистской организацией и запрещена) в феврале-апреле 2026 года выпустила четвёртое поколение своей флагманской открытой модели.
Семейство Llama 4 включает три версии:
- Llama 4 Scout — 109 миллиардов параметров, контекстное окно 10 миллионов токенов (в 80 раз больше, чем у предшественника Llama 3). Запускается на одной видеокарте NVIDIA H100.
- Llama 4 Maverick — 400 миллиардов параметров суммарно, из которых активно задействуются 17 миллиардов на каждый запрос (архитектура 128 экспертов MoE). По независимым бенчмаркам — уровень GPT-4o.
- Llama 4 Behemoth — флагман с более чем 400 миллиардами параметров, приближающийся по качеству к GPT-5 в задачах reasoning (рассуждения и логика).
DeepSeek V3 и V4 Pro от DeepSeek AI
DeepSeek — китайский стартап, ставший главной сенсацией в ИИ за 2025-2026 годы.
Флагманская модель DeepSeek V3 (актуальная версия V3-0324) использует архитектуру MoE: 671 миллиард параметров суммарно, из которых активируются 37 миллиардов при обработке каждого запроса. По ряду бенчмарков сопоставима с GPT-4o.
Параллельно существует DeepSeek R1 — специализированная reasoning-модель (модель рассуждений), заточенная под сложные логические задачи, математику и программирование.
К апрелю 2026 года компания представила DeepSeek V4 Pro, продолжающий бросать вызов западным лидерам. Все ключевые версии доступны с открытыми весами на Hugging Face.
Важный нюанс: DeepSeek запрещён для использования в государственных учреждениях США из соображений национальной безопасности. В России открытые веса можно использовать локально.
Подробнее о DeepSeek читайте в нашей статье: DeepSeek (Дипсик): что это за нейросеть и почему весь мир говорит о «китайском убийце ChatGPT»
Gemma 4 от Google
2 апреля 2026 года лаборатория Google DeepMind представила Gemma 4 — четвёртое поколение своей открытой линейки, построенное на технологиях Google Gemini.
Семейство состоит из четырёх версий:
- Gemma 4 E2B — 2,3 миллиарда активных параметров, работает прямо на смартфоне
- Gemma 4 E4B — 4,5 миллиарда активных параметров, ноутбук справляется
- Gemma 4 26B MoE — 26 миллиардов параметров с архитектурой MoE, при инференсе (выполнении запросов) активирует лишь 3,8 миллиарда
- Gemma 4 31B Dense — 31 миллиард параметров плотной архитектуры, флагман линейки
Модель заточена под агентные рабочие процессы (agentic workflows) — сценарии, когда ИИ самостоятельно выполняет многошаговые задачи без участия человека.
Хотите глубже изучить Gemma 4? Читайте подробный разбор: Gemma 4 от Google: самая умная открытая нейросеть 2026 года
Другие заметные открытые модели

Риски и ограничения открытых моделей
Открытые нейросети — не панацея. У них есть конкретные ограничения, о которых важно знать перед внедрением.
Безопасность: обратная сторона свободы
В феврале 2026 года исследователи обнаружили множество публичных серверов, где open source LLM работали с полностью удалёнными защитными ограничениями. Проблема в природе открытого кода: фильтры можно отключить, ограничения переписать. Для злоумышленников это лазейка — они могут разворачивать нецензурированные версии моделей для создания вредоносного контента.
Для бизнеса это означает: запуская открытую модель, вы сами несёте ответственность за её безопасное поведение. Встроенных фильтров компании-разработчика уже нет.
Требования к железу
Полноразмерные флагманы требуют серьёзного оборудования:
- Небольшие модели (до 7B параметров) — от 8 ГБ видеопамяти
- Средние (13-30B) — от 24 ГБ VRAM
- Флагманы (70B+) — несколько GPU с суммарно 80-320 ГБ VRAM
Это либо значительные инвестиции в оборудование, либо аренда облачных серверов — что нивелирует часть экономии.
Лицензионные тонкости
Не все «открытые» модели одинаково свободны:
- Apache 2.0 (Gemma 4, Phi-4) — полная коммерческая свобода
- Llama Community License — бесплатно, но крупные компании (700M+ MAU) должны получить разрешение Meta
- Некоторые модели требуют указания авторства или раскрытия дообученных версий
Отсутствие гарантий SLA
Работаете через облачного провайдера — всё хорошо. Но если вы сами разворачиваете модель, её доступность целиком на вашей ответственности. Нет службы поддержки, которая поднимет сервер в 3 ночи.
Нестабильность экосистемы
Проект может потерять поддержку разработчиков. Обновления выходят нерегулярно. Документация бывает неполной. Всё это — реальные операционные риски для бизнеса, который строит продукты на открытых моделях.
Как бизнес применяет открытые модели прямо сейчас
Открытые нейросети — не только про «запустить у себя вместо ChatGPT». В 2026 году есть три основных сценария применения.
Сценарий 1: Работа с конфиденциальными данными
Медицина, юриспруденция, финансы, HR — там, где данные клиентов нельзя отправлять на внешние сервера. Компании разворачивают Llama 4 или DeepSeek V3 на собственных серверах и получают мощный ИИ без утечки данных.
Сценарий 2: Дообучение (fine-tuning) под нишу
Открытые модели можно дообучить на своих данных: документах, скриптах продаж, базе знаний компании. Результат — нейросеть, которая говорит языком вашего бизнеса и знает ваш продукт. Закрытые модели такого не позволяют.
Сценарий 3: Основа для ИИ-агентов
Открытые модели активно используют как «движок» для ИИ-агентов (AI agents) — автономных программ, которые самостоятельно выполняют задачи: обрабатывают заявки, ведут переписку с клиентами, анализируют данные.
Хотите разобраться, как работают ИИ-агенты в бизнесе и как их запустить без технических знаний? Читайте подробный гайд: ИИ-агенты, нейросотрудники и ИИ-ассистенты: руководство для бизнеса 2026
Если вы уже думаете о монетизации навыков работы с открытыми моделями — загляните в статью Заработок на ИИ в 2026 году: все реальные способы — от фриланса до своего сервиса. Там разобраны конкретные схемы, как превратить знания об ИИ в доход.
Готовый промпт: выберите лучшую открытую нейросеть под вашу задачу
Скопируйте этот промпт в любой доступный вам ИИ и получите персональный разбор:
Моя ситуация:
- Моя ниша и вид бизнеса: [опишите, например: онлайн-школа, e-commerce, юридическая фирма]
- Задача, которую хочу решить с помощью нейросети: [например: обработка входящих заявок, генерация контента, анализ документов]
- Конфиденциальность данных: [критична / не критична]
- Технические ресурсы: [есть свои сервера / только облако / нет IT-специалистов]
- Бюджет на ИИ в месяц: [укажите диапазон]
На основе моей ситуации:
- Порекомендуй 2-3 наиболее подходящих LLM-модели (как открытые, так и закрытые) с пояснением, почему именно они
- Для каждой модели укажи: способ запуска, примерную стоимость, ключевые ограничения
- Предложи конкретный первый шаг для внедрения
- Если моя задача хорошо решается ИИ-агентом — опиши оптимальную архитектуру агента
Где запустить этот промпт:
- ChatGPT (chat.openai.com) — GPT-5.4 или GPT-5.4 Thinking
- Claude (claude.ai) — Claude Sonnet 4.6 или Opus 4.6, отличен для структурных разборов
- Perplexity AI — даст ответ со свежими данными из интернета; подробнее о нём в статье Perplexity AI: что это такое и как работает в 2026 году
- Алиса от Яндекса (ya.ru) — российский ИИ-ассистент, доступен без VPN
- Телеграм-бот «Творец ИИ» — доступ к множеству нейросетей и режимов работы в одном боте: t.me/BoreyCreator_ai_bot
FAQ: частые вопросы об открытых нейросетях
Что значит «открытая нейросеть» простыми словами?
Открытая нейросеть — это ИИ-модель, чьи веса (числовые параметры, определяющие поведение модели) опубликованы в открытый доступ. Любой может скачать её, запустить у себя и модифицировать. Аналог: операционная система Linux против Windows.
Открытые нейросети хуже закрытых?
В 2026 году разрыв минимален. Llama 4 Maverick и DeepSeek V4 Pro сопоставимы с GPT-4o по большинству бенчмарков. Для самых сложных задач рассуждения (reasoning) закрытые флагманы ещё чуть впереди, но для 90% бизнес-задач открытые модели уже полностью справляются.
Можно ли использовать открытые нейросети бесплатно?
Сами веса моделей бесплатны. Вы платите только за вычислительные ресурсы — аренду GPU-сервера или покупку видеокарты. Для небольших задач можно запускать компактные модели (Gemma 4 E2B, Phi-4) даже на ноутбуке.
Безопасно ли использовать открытые нейросети в бизнесе?
Безопасно — если правильно настроить. Данные не покидают ваш сервер, что хорошо для конфиденциальности. Но безопасность самой модели — ваша ответственность: встроенные фильтры можно отключить, и никто кроме вас не следит за поведением ИИ.
Что такое fine-tuning (дообучение) и зачем оно нужно бизнесу?
Fine-tuning — это дополнительное обучение открытой модели на ваших данных: скриптах продаж, документах, описаниях продуктов. В результате нейросеть начинает говорить языком вашей компании и знает ваш продукт. Закрытые модели так обучить нельзя.
Какие открытые нейросети лучшие в 2026 году для запуска в России?
Для российских пользователей без ограничений доступны: Llama 4 (при условии локального запуска), Gemma 4 (Apache 2.0, полная свобода), Qwen 3 от Alibaba, DeepSeek V3/V4 (открытые веса). Согласно инициативе Минцифры 2026 года, именно локальные open source модели рассматриваются как приоритетная альтернатива зарубежным облачным сервисам.
Как открытые нейросети связаны с вайбкодингом и разработкой ИИ-агентов?
Открытые модели — популярный движок для вайбкодинга (создания кода с помощью ИИ) и ИИ-агентов. Они не зависят от лимитов внешнего API, работают локально и могут быть дообучены под конкретную задачу разработки. Подробнее о вайбкодинге читайте в статье Вайбкодинг (Vibe Coding): что это такое и почему весь мир кодит «по вайбу».
Вывод
Открытые нейросети в 2026 году — это не компромисс, а полноценная альтернатива коммерческим системам для большинства задач. Llama 4 Maverick уровня GPT-4o, Gemma 4 работает прямо на ноутбуке, DeepSeek V4 Pro лидирует среди open source в логических задачах.
Данные по моделям в статье собраны на основе анализа топ-20 изданий в нише с помощью системы Perplexity, а также редакционного опыта команды Wake Up Marketing.
Для бизнеса вопрос уже не «использовать ли открытые модели», а «какую задачу с их помощью решать первой». Начните с аудита: какие данные у вас конфиденциальны, какие задачи повторяются ежедневно, где больше всего теряется время сотрудников.
Хотите глубже разбираться в ИИ-инструментах, получать первыми разборы новых нейросетей и видеть, как предприниматели зарабатывают на ИИ в 2026 году?